Zusammenfassung: Um einen erfolgreichen und langweiligen Go-Live zu gewährleisten, ist es entscheidend, von Anfang an sicherzustellen, dass Ihre Daten bereinigt und business-ready sind. Die Datenbereinigung wird ein Schlüssel dazu sein, Probleme während des Implementierungsprozesses zu minimieren und sicherzustellen, dass die Daten ordnungsgemäß funktionieren, was zu einem reibungslosen Übergang führt.
Es dürfte mittlerweile allen Unternehmen, die ein ERP einsetzen, bewusst sein, dass die Korrektheit, Vollständigkeit, Integrität und Aktualität der Stammdaten DER Schlüssel zu einer reibungslosen und fehlerfreien Nutzung des ERP-Systems sind. Das war im SAP R/2 so genauso wie im R/3 und jetzt im S/4HANA ist das immer noch so.
Folgende Anekdote mag das verdeutlichen:
Ein guter Kollege von mir macht Management-Schulungen für Firmen, die SAP nutzen. Er möchte den Managern im Wesentlichen zwei Aspekte näherbringen: Erstens ein Grundverständnis für die funktionsübergreifende Integration. Und zum zweiten die Sensibilisierung für die Wichtigkeit der Stammdaten. Aus diesem Grund macht er es sich irgendwann mitten im Workshop auf seinen Stuhl bequem, schlägt die Zeitung auf und fängt an zu lesen. Dies macht er solange, bis er gefragt wird, was der dort jetzt macht. Seine Antwort lautet dann: Ich zeige Ihnen gerade, wie die Arbeit an einem SAP-Arbeitsplatz aussieht, wenn die Stammdaten in Ordnung sind.
Automatisierte Abwicklung
Und genauso verhält es sich. Gerade das SAP ERP System kann in weiten Teilen voll automatisiert und ohne manuelle Eingriffe ganze Geschäftsprozesse end-to-end abwickeln, wenn die Stammdaten entsprechend vollständig und korrekt gepflegt sind. Wenn dem nicht so ist, verwendet das Unternehmen in der Regel unglaubliche Ressourcen darauf, diesem Umstand mit permanenten operativen Eingriffen in die einzelnen Transaktionen oder anderen Workarounds Abhilfe zu schaffen. Diese Tätigkeiten sind in der Regel sinnentleert und stupide und tragen keinen Deut zur Wertschöpfung im Unternehmen bei. Nutzen Sie also die Chance der Umstellung auf S/4HANA und beseitigen Sie dieses Defizit! Im Folgenden werde ich Ihnen aufzeigen, wie dabei sinnvoll vorgegangen wird und was es sinnvollerweise für Tools und Unterstützung dafür braucht!
Ich habe in den von mir geleiteten Projekten in den ersten zehn Jahren das Thema Datenbereinigung und Datenmigration als Projektleiter immer sehr fokussieren müssen und es sind immense Aufwände kritischer Key-User in diesen Bereich geflossen, um Daten manuell zu bereinigen und in mehreren Quellen konsistent und integer zu pflegen, bis diese dann endlich migriert wurden … und das dann zumeist mit einem nicht befriedigenden Ergebnis, weil dann doch irgendwo etwas verloren ging oder übersehen wurde. Ich selbst hatte mich schon tief in die Möglichkeiten der LSMW eingearbeitet und den SAP-seitigen Teil der Migration in vielen Projekten komplett selbst gestaltet. Insgesamt floss aber immer viel zu viel Aufwand in diesen Bereich und die Ergebnisse waren unbefriedigend.
Geändert hat sich das, als ich im Jahr 2007 im Rahmen eines Projekts in Kairo auf eine auf SAP-Datenmigration spezialisierte Firma gestoßen bin, die die ganze Thematik in einer vollständig anderen Art und Weise angegangen ist. Ich war in dem Projekt als Integrationsmanager tätig und war sehr überrascht, als der Teilprojektleiter der Datenmigration mir mitteilte, dass ich ihm ab jetzt drei Tage vorher Bescheid sagen könne, wenn ich den Integrationsmandanten für den Integrationstest mit den kompletten produktiven Datenbestand beladen haben möchte. Ich dachte, er scherzt, aber schlussendlich ist es genau so gekommen und die Datenqualität im Integrationssystem war sechs Monate vor dem Go-Live hervorragend – und zwar in allen Aspekten.
Das hat mich damals so beeindruckt, dass ich mich intensiv mit dem Vorgehen und dem Toolset (middleware) (welches heute bei der SAP auf der offiziellen Preisliste als SAP Advanced Data Migration (ADM) geführt wird) beschäftigt habe.
Hier die aus meiner Sicht wesentlichen Erfolgsfaktoren:
- Das Thema Datenmigration wird in einem evolutionären Prototyping Ansatz abgearbeitet – es gilt das Prinzip „Load often – Load all“
- Die Daten im Altsystem sind, sobald alle Datenquellen identifiziert und an die Middleware angebunden sind, fest im Griff und unter Kontrolle des Datenmigrationsteams und alle für die formale Datenqualität notwendigen sowie für die Business-Readiness der Daten hinreichenden Cleansing Massnahmen werden von diesem auf Feldebene initiiert, überwacht und reported
- Die Methodik ist einfach, eingängig und es ist sichergestellt, dass wenn die Mitarbeiter sich daran halten, keine flüchtigen Fehler passieren
- Es besteht die Möglichkeit, für einen Load noch nicht bereinigte Daten nach bestimmten Regeln „zu faken“, also sie laden zu können, ohne die weiterhin notwendige Cleansing Maßnahme aus den Augen zu verlieren
- Quellsysteme (SAP R/3 und andere) und Zielsystem (S/4HANA) sind quasi permanent miteinander verbunden; die Quelldaten werden in die Staging-Area der Middleware geladen, dort regelbasiert konvertiert und auf ihre Konformität mit der aus dem Zielsystem geladenen Systemkonfiguration (Customizing) geprüft – Disharmonien werden natürlich reportet
- Das Toolset verfügt über eine Reihe von eingebauten Logiken und Werkzeugen, die das Data-Cleansing effektiv unterstützen, wie z.B.:
- Automatisiertes ausgrenzen aller inaktiven Datensätze (solche, die nicht übernommen werden) von künftigen Cleansing Aktivitäten
- Identifikation doppelter Datensätze und konsistente Zusammenführung aller abhängigen Daten auf den definierten Gewinner (den Satz der übernommen wird)
- Sicherstellung der formalen und inhaltlichen Konsistenz des kompletten zu ladenden Datenbestandes (z.B. das zu allen zu übernehmenden Bestellungen die Lieferanten / Materialien / Infosätze und Source Listen vorhanden sind, wenn die gemäß den vorgenommenen Einstellungen und gepflegten Daten notwendig ist oder selbiges auch für alle in der Produktion relevanten Daten)
- Automatiiserte Überführung in neue Datenstrukturen im S/4HANA (das Musterbeispiel hierfür ist die Zusammenführung von Kunden/Debitoren und Lieferanten/Kreditoren in das neue vereinheitlichte Datenobjekt Business Partner
- Einfache Web-basierte Oberflächen für die durch das Business notwendige Datenbearbeitung wie z.B. die Festlegung des „Gewinner“ bei doppelten Stammdaten und auch der Anreicherung von Datensätzen (z.B. um Felder, die es im Altsystem noch nicht gibt; einschl. diverser Upload-Möglichkeiten) inklusive der Möglichkeit, alle getroffenen Entscheidungen wieder zu korrigieren
- Tracking und Tracing für jede Aktivität, die maschinell oder manuell in dem Toolset erfolgt und somit eine automatisierte Erstellung einer revisionssicheren Dokumentation der kompletten Datenmigration (Stammdaten, Transaktionsdaten und historische Datenbestände, die übernommen werden)
und somit den involvierten Business Usern erlauben, sich geführt ausschließlich auf die inhaltlich zwingend durch sie zu treffenden Entscheidungen im Zusammenhang mit der Datenmigration zu fokussieren keine wertvollen Zeiten mit banalen Data-Cleansing Aufgaben zu verschwenden.
- Durch diese Vorgehensweise ist zudem sichergestellt, dass manuelle Datenerfassungen im Projekt, insbesondere zu Testzwecken auf ein Minimum reduziert werden können, da die Daten bereits zu frühen Zeitpunkten in guter Qualität in jedem Mandanten zur Verfügung gestellt werden können; dies bedingt natürlich einen entsprechend frühen Start des Datenmigration-Workstreams – meine Empfehlung ist, dies von Anfang an vollständig unter Hinzuziehung eines entsprechenden kompetenten Partners (hierzu kann ich gerne Empfehlungen geben) bei der Projektplanung mit einzubeziehen; nur dann werden Sie auch den maximalen Nutzen hieraus ziehen.
Die grundlegende Architektur so einer Lösung sieht wie folgt aus:
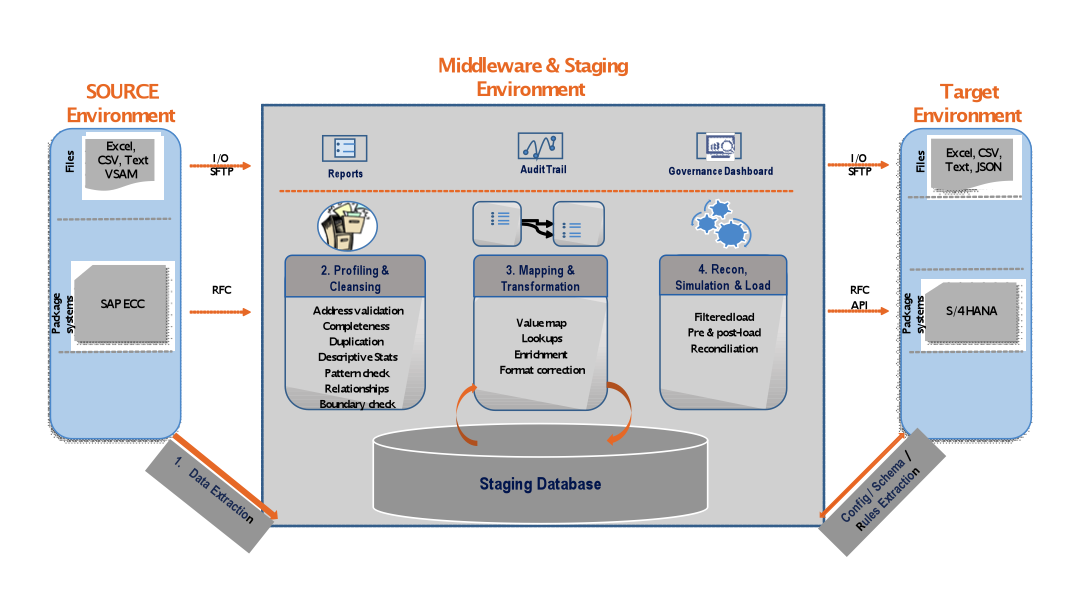
Aufgrund der damaligen Erfahrung und Erkenntnisse habe ich in den von mir geleiteten Projekten, immer wenn diese über eine nennenswerte Herausforderung im Bereich Data-Cleansing / Datenmigration verfügten, den Kunden davon überzeugt, einen entsprechenden Migrationspartner hinzuzuziehen. Dabei habe ich insbesondere auch die folgende Erfahrung gemacht: Der Migrationspartner plant und managet den Datenmigration-Workstream gemäß meinen Erfahrungen vollkommen eigenständig inklusive aller damit im Zusammenhang stehenden Planungen, Risiken und Probleme – DAS HEISST AUS SICHT DER PROJEKTLEITUNG WIE AUCH DES KUNDEN IST DER MEISTENS KRITISCHSTE FAKTOR DER SAP EINFÜHRUNG IN TROCKENEN TÜCHERN UND ES KÖNNEN ANDERE THEMEN VIEL STÄRKER FOKUSSIERT WERDEN. Und das ist sehr gut so. Denn das ganze organisatorische Change Management bedarf in der Regel viel mehr Aufmerksamkeit und Zeit durch die involvierten Key-User, aber ich will hier nicht abschweifen.
Hier noch einige Empfehlungen zum Vorgehen bei der Datenbereinigung, um diese möglichst effektiv zu gestalten:
Unterscheiden Sie zwischen unabhängigen und abhängigen Daten:
- Unabhängige Daten können in das SAP-System eingegeben werden, ohne das ein Bezugsdatenobjekt vorhanden sein muss; dies sind offensichtlich im Wesentlichen der Materialstamm, der Business-Partner-Stamm (Kunden/Debitoren & Lieferanten/Kreditoren) und der Sachkontenstamm.
- Abhängige Daten sind all die Datenobjekte, die, um sie im SAP-System anzulegen, ein Bezugsobjekt (unabhängiges oder abhängiges) benötigen; eine Stückliste benötigt einen Materialstamm, ein Arbeitsplan ebenfalls, eine Produktionsversion eine Stückliste und einen Arbeitsplan, ein Einkaufsinfosatz braucht einen Lieferanten und ein Material usw.
Strukturieren Sie die ganze Abarbeitung der Datenbereinigung in die folgenden Schritte und arbeiten Sie diese möglichst sequentiell ab:
- Active Record Determination: Festlegung, welche Stammsätze in das neue System übernommen werden sollen; Beispiele. Alle Kreditoren/Debitoren mit offenen Posten, offenen Aufträgen oder Bestellungen (das ist quasi ein Muss). Alle Materialien, die in den letzten zwei Jahren benutzt wurden usw.⇒ fokussieren Sie bei diesem Schritt auf die unabhängigen Daten, da die abhängigen ja als solche implizit mit klassifiziert werden⇒ ALLE WEITEREN CLEANSING AKTIVITÄTEN WERDEN NATÜRLICH NUR FÜR AKTIVE RECORDS DURCHGEFÜHRT, DER SCHRITT IST SO WICHTIG; WEIL DAMIT WESENTLICH DER UMFANG DER WEITER ZU CLEANSENDEN DATEN FESTGELEGT WIRD
- Required Field Content: Sicherstellen, dass alle künftig im S/4HANA zu nutzenden Felder (primär Mussfelder und am besten auch optionale Felder) gemäß der Felddefinition/Konvertierungsregeln befüllt werden können⇒ fokussieren Sie bei diesem Schritt wieder auf die unabhängigen Daten, da für jeden unabhängigen Datensatz, der aufgrund fehlender Daten nicht geladen werden kann, auch diverse abhängige verloren gehen; relevant ist es natürlich trotzdem für alle
- Formal Field Content: Sicherstellen, dass alle künftig im S/4HANA zu nutzenden Felder (primär Mussfelder und am besten auch optionale Felder) gemäß der Felddefinition/Konvertierungsregeln formal korrekt befüllt werden; das bedeutet zum Beispiel, das in der Planlieferzeit eine Zahl steht, ob diese inhaltlich korrekt ist, ist nur zweitrangig relevant⇒ fokussieren Sie bei diesem Schritt wieder auf die unabhängigen Daten, da für jeden unabhängigen Datensatz, der aufgrund fehlender Daten nicht geladen werden kann, auch diverse abhängige verloren gehen; relevant ist es natürlich trotzdem für alle⇒ Wenn dieser Cleansing Schritt erledigt ist, ist der Datenload in einer Qualität, die für einen Integrationstest ausreichen sollte
- Business Readiness: Sicherstellen, dass alle künftig im S/4HANA zu nutzenden Felder (primär Mussfelder und am besten auch optionale Felder) gemäß der Felddefinition/Konvertierungsregeln mit einem inhaltlich korrekten befüllt werden. Das bedeutet zum Beispiel, das in der Planlieferzeit in dem Material die Zahl steht, die inhaltlich korrekt ist und zu einer entsprechenden korrekten Steuerung der davon abhängigen Planungen im ERP führt⇒ Während die Schritte 2 und 3 „gefaked“ werden können, ist das bei diesem Schritt nicht möglich; hier muss das Business die Daten prüfen und am besten durch Unterschrift freigeben⇒ ICH HABE MITTLERWEILE IN VIELEN UNTERNEHMEN, DIE DAS SAP ERP SCHON SEIT JAHREN NUTZEN, LEIDER FESTSTELLEN MÜSSEN, DASS DEN AN DER PLANUNG BETEILIGTEN MITARBEITENDEN HÄUFIG WEDER DER ZUSAMMENHANG ALLER AN DER ERP STEUERUNG BETEILIGTEN FELDER NOCH DEREN EINZELNE FUNKTION ALS SOLCHE WIRKLICH BEKANNT IST. DIES IST EIN AUS MEINER SICHT FATALER ZUSTAND, DEM UNBEDINGT IM VORWEGE DIESES CLEANSING SCHRITTES ABHILFE GESCHAFFEN WERDEN MUSS, DA ANSONSTEN DIE FUNKTIONALITÄT DER NEUEN ERP DIREKT FALSCH GESTEUERT WIRD UND ERGO ZU FALSCHEN ERGEBNISSEN FÜHRT. HELFEN TUT DABEI DIE ZUR VERFÜGUNG STELLUNG EINER ÜBERSICHT MIT DER KONKRETEN VORGESEHENEN NUTZUNG ALLER AN DER PLANUNG BETEILIGTEN FELDER (S. BEISPIEL) UND AUCH EIN ASSESSMENT FÜR ALLE AN DER PLANUNG BETEILIGTEN MITARBEITENDEN UND FÜHRUNGSKRÄFTE, UM DEREN DIESBEZÜGLICHEN WISSENSTAND/SCHULUNGSBEDARF ZU ERMITTELN (HIERZU KANN ICH GERN AUF SEPARATE NACHFRAGE DURCHFÜHRUNGSEMPFEHLUNGEN GEBEN)⇒ Wenn dieser Cleansing-Schritt vollständig abgeschlossen ist, ist der Datenload in einer Qualität, die für den User-Acceptance Test und einen Boring Go-Live ausreichen wird
Ich habe in den vergangenen 12 Jahren als Projektleiter Datenmigrations-Erfahrungen in enger Zusammenarbeit mit unterschiedlichen Anbietern und deren Toolsets gemacht – aus meiner Sicht bietet das SAP ADM in Verbindung mit der Beauftragung eines kompetenten Partners das vollständigste Lösungsportfolio
Hier eine aggregierte Übersicht über den Nutzen und die impliziten Risiken der meisten anderen Ansätze:
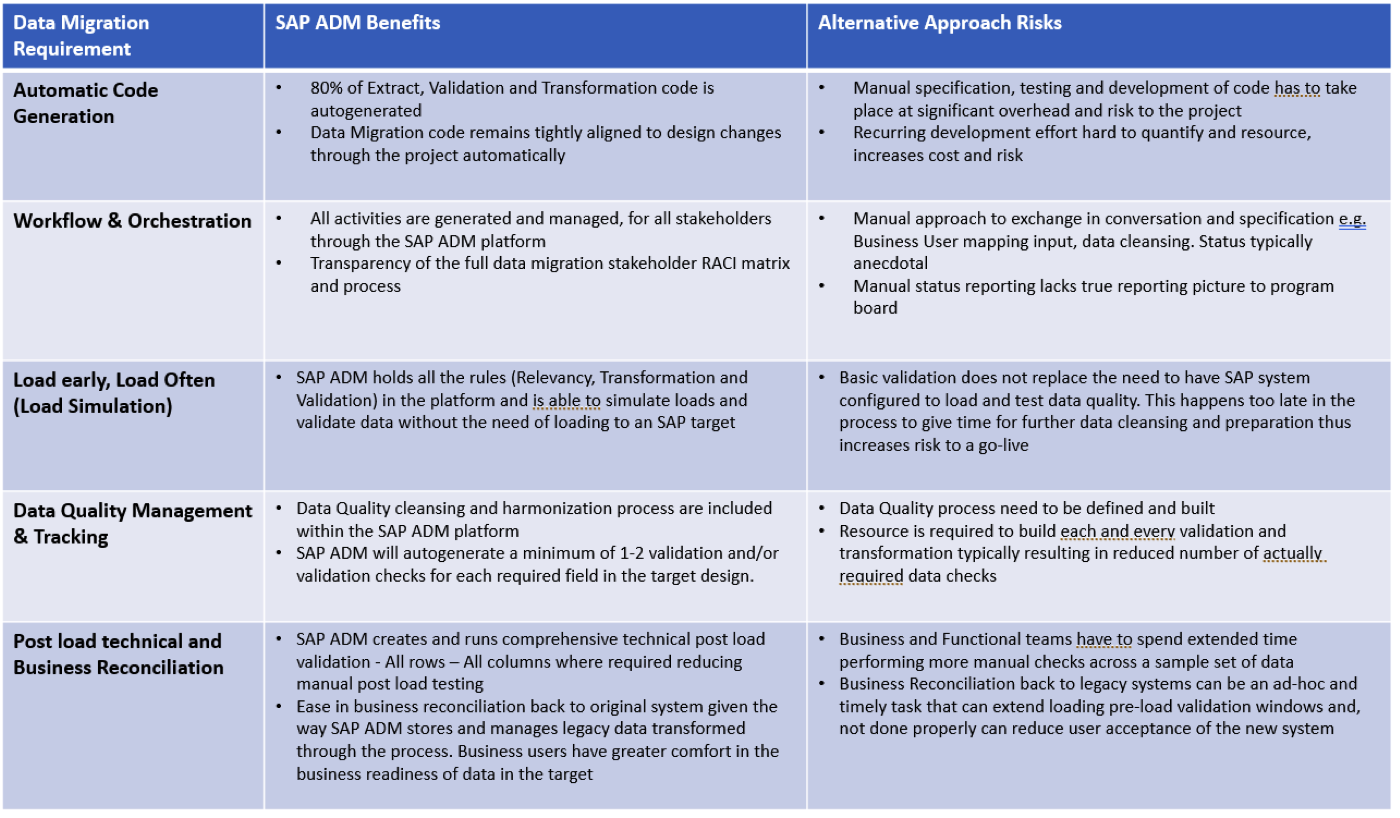
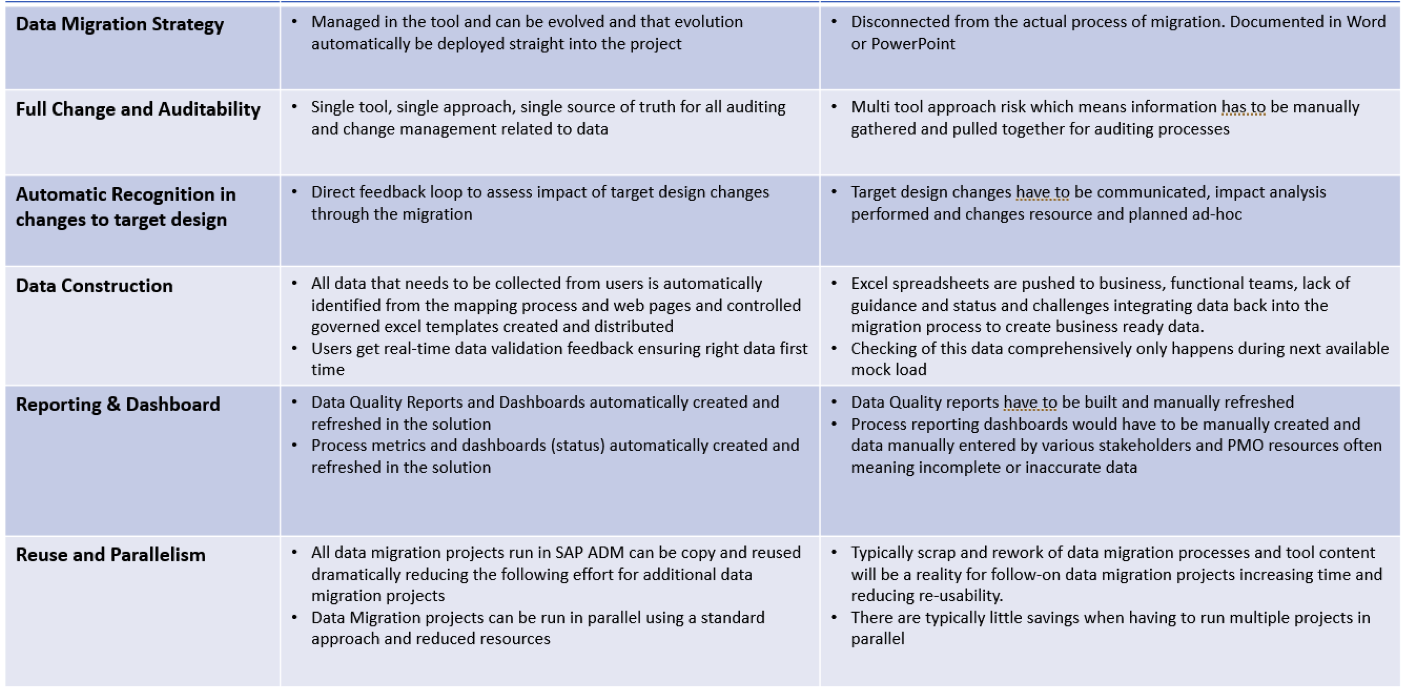
Quelle: Syniti
Es ist sicherlich so, dass der Einsatz von SAP ADM mit einem entsprechend kompetenten Partner einen massiven Budgetblock darstellen wird, deshalb hier eine Übersicht über die Einsparpotentiale:
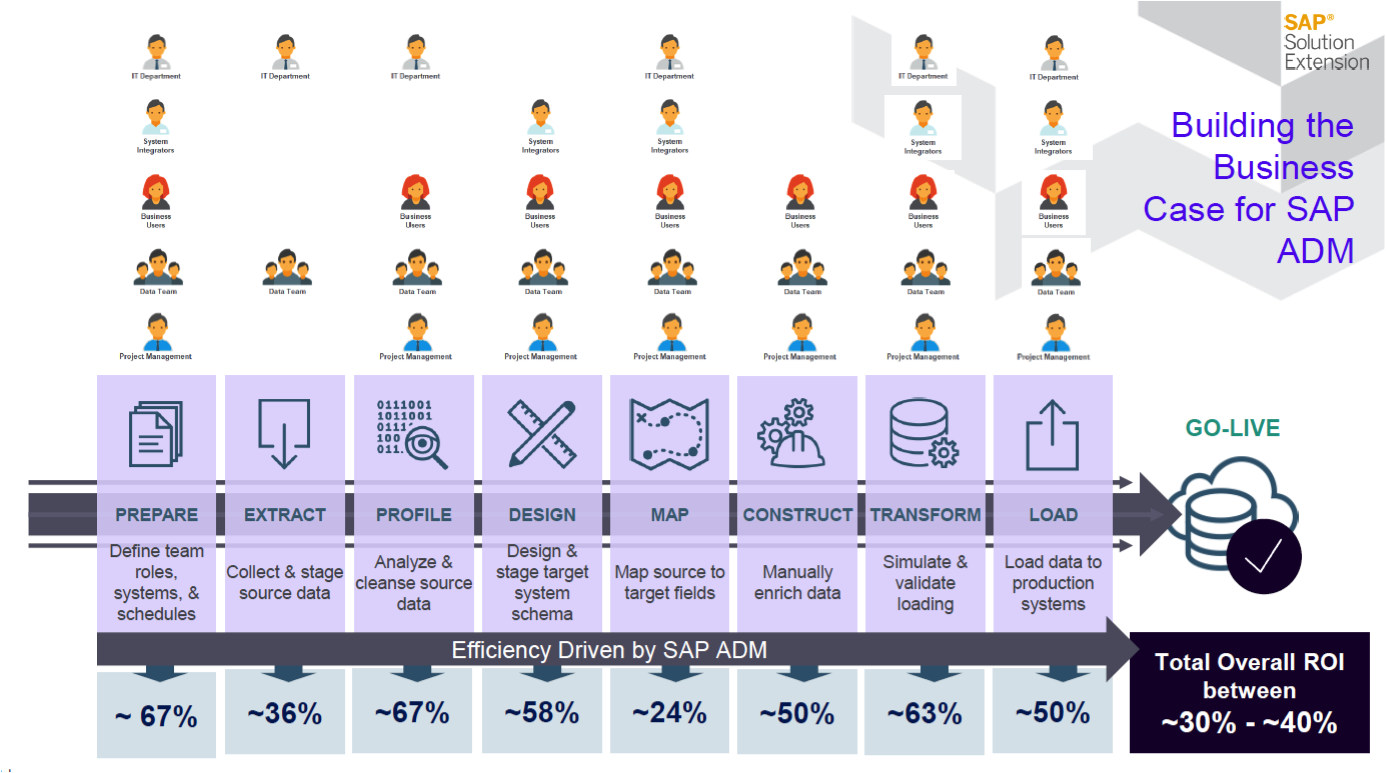
Quelle: Syniti
Wie auch eine Übersicht über die Auswirkungen auf Risiken, Ressourcen und Projektlaufzeit:
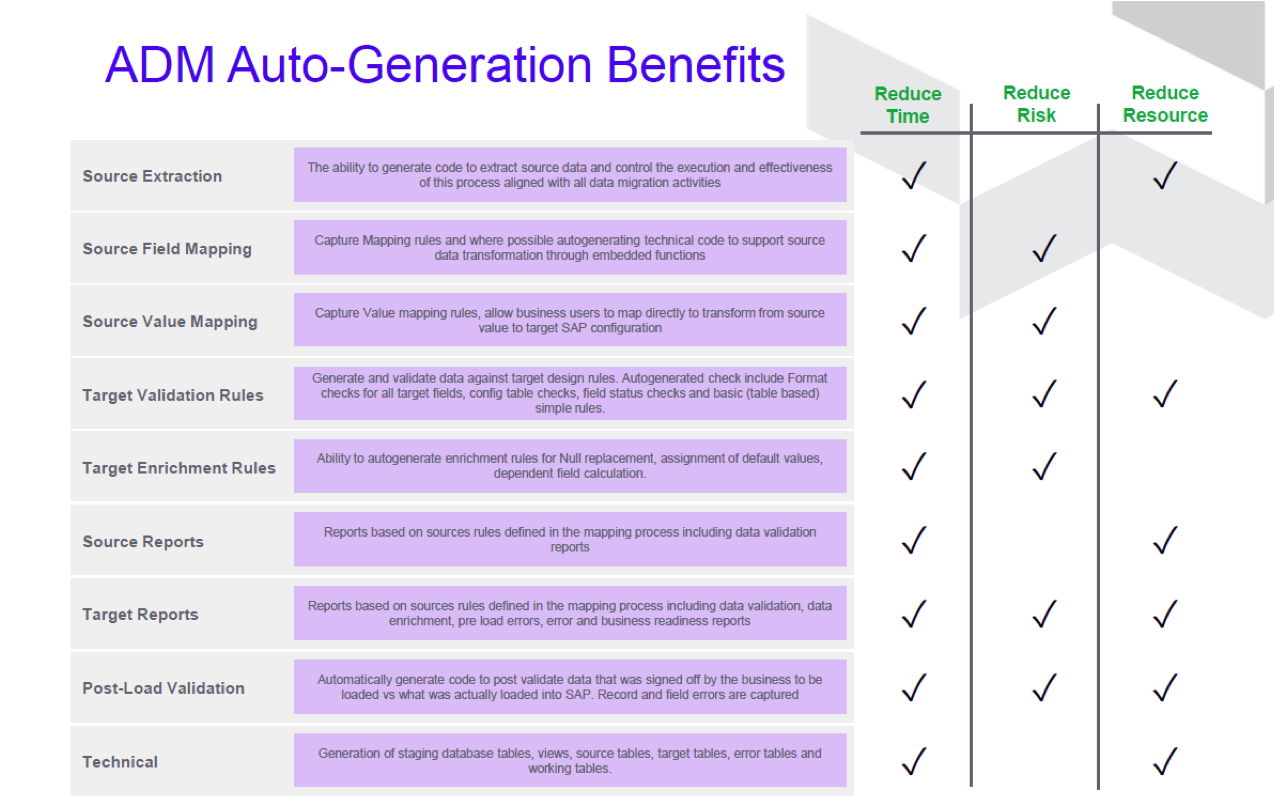
Quelle: Syniti
Gerne teile ich mit Ihnen auf Anfrage auch meine gemachten Erfahrungen mit anderen ähnlichen Toolsets und den jeweils involvierten Partnern. Für weitere Informationen besuchen Sie gern die folgenden Websites:
https://www.syniti.com/solutions/data-migration/#sap-users
oder auch
Eine Übersicht über unsere eigenen Tools für das Projektmanagement finden Sie hier!